文智能相对论,作者沈浪
Long-LLM(长文本大模型)时代似乎来得有些突然,而引爆这场热潮的,竟是一家由清华学霸牵头的本土 AI 初创企业。
前不久,月之暗面(Moonshot AI)公司宣布旗下对话式 AI 助理产品 Kimi 应用现已支持 200 万字无损上下文输入。
对比去年 10 月份 Kimi 上线时仅支持的 20 万字,这一波升级直接提升了 10 倍文本处理能力,同时也引起了强烈的市场反应,特别是在资本市场,Kimi 概念股应运而生,诸如九安医疗、华策影视、中广天择等都受益于 Kimi 概念而实现了股价不同程度的涨幅。
这些刺激更让大模型领域彻底卷起了长文本大战。
“长文本”大战,卷的不是字数而是财力
阿里率先完成自家的大模型产品升级,强化长文本处理能力,免费面向大众开放最高 1000 万字的长文本处理能力。
360 则紧随其后,宣布旗下 360 智脑正式内测 500 万字的长文本功能,并在 360AI 浏览器开放给用户使用。
而百度也宣布在下个月进行版本升级,开放长文本能力,文字范围会在 200 万-500 万字。
目前,文心一言的文本上限大致为 2.8 万字。而像 GPT-4Turbo-128k 公布的文本范围也不过为 10 万汉字,Claude3200k 上下文约 16 万汉字。
可以说,这一波热潮直接把国内的大模型厂商一下子都拉进了百万量级的长文本竞赛,而主流厂商的入局也为这场“长文本”大战增添了很多看头。
目前来看,“长文本”大战的赛点主要呈现在两个方面。
一方面,是大模型的支持文本参数。类似阿里通义千问的 1000 万字、360 智脑的 500 万字、百度文心一言的 200 万-500 万字、Kimi 的 200 万字等等,都在极力向市场争“彩头”,告诉用户自家的长文本处理能力足够“长”。
另一方面,是长文本处理能力的开放程度。有意思的是,Kimi 是免费开放给用户使用的,阿里通义千问的长文本处理功能也是免费的,360 智脑、百度文心一言也没有要收费的意思。——以“长文本”大战为例,今年的大模型竞争远比去年要“卷”得多。
还记得去年大火的妙鸭相机,以及各式各样的图片生成式服务,都或多或少地通过各种形式如充值、办会员等,要求用户付费才能体验。
今年大模型领域的这把“火”烧得旺,也烧的离奇地“free”。
为什么?
Kimi 自升级以来,就有大量用户不断涌入,激增的流量更是一度让月之暗面(Moonshot AI)的服务器承受了巨大的压力,一度陷入宕机,旗下的 App 和小程序都无法正常使用。
根据月之暗面(Moonshot AI)发布的官方消息,从 3.20 观测到流量异常增高后,已经进行了 5 次扩容工作。推理资源会持续配合流量进行扩容,以尽量承载持续增长的用户量。
简单来说,用户对长文本功能是非常有兴趣的,相关的市场需求还在保持持续性的、爆炸性的增长。同时,大量的用户涌进,不仅提高了大模型产品的知名度,更重要的是在大量用户的基础上通过类似于 UGC 的模式去探索大模型的应用,或许更能进一步推动 Long-LLM(长文本大模型)的商业化进程。
当然,在这个过程中,不可避免地就得投入大量资金,一旦商业化加速,大模型厂商就得做好“卷”财力的准备。
阿里通义千问目前免费对所有人开放高达万页的文档处理能力,如果要计算成本,按照目前最便宜的市价 0.1 元/页,10000 页的文档光解析费用就要 1000 元,这还不包括解析完成之后大模型处理文档的成本。考虑到通义千问网页、APP、钉钉等多个端口的用户基数,需要投入的资金恐怕不会是个小数目。
大模型的商业化在开始阶段并非“赚钱”,而是“烧钱”。
长文本,直接“接驳”商业化场景
在大模型的商业化进程上,长文本的爆火是很关键的一环。
就大模型的技术原理而言,解决长文本问题是必要的。因为文本长度的提高,对应的模型能解决问题的边界也将大幅提升,两者呈现出明显的正向关系。
传统的文本处理模型受限于训练结构,可支持的文本范围都不算长,在处理复杂任务和深度专业知识(这一类知识往往都是长篇巨著)时,只能拆解输入训练,由此就有可能导致输出的结果上下文逻辑不连贯不顺畅等问题。
区别于传统的文本处理模型,长文本模型就具备更准确的文本理解和生成能力以及更强大的跨领域迁移能力。这对于打造垂直领域的行业专家是一个非常必要的能力支持,比如面向一些长篇巨制的医疗文献、法律文件、财务报告等,长文本模型就具备更好的理解能力,对应完成跨领域学习和应用,从而打造出更专业的医疗助理、法律助理以及金融助理等应用。
话不多说,实践一下。
在这里,「智能相对论」向阿里通义千问相继“投喂”了几本长达数百页的专业书籍,涵盖以《高产母猪饲养技术有问必答》为代表的农业养殖、以《犬猫营养需要》为代表的宠物喂养等等小众领域。
结果所能实现的效果确实令人惊讶,阿里通义千问不仅能高度概括总结这些长篇巨著的主要内容,还能有针对性的给出具体篇章的知识解答。比如,在《高产母猪饲养技术有问必答》一书中,「智能相对论」向其提问“夏季高温提问应该如何饲养母猪?”很快就得到了书中的精炼解答。
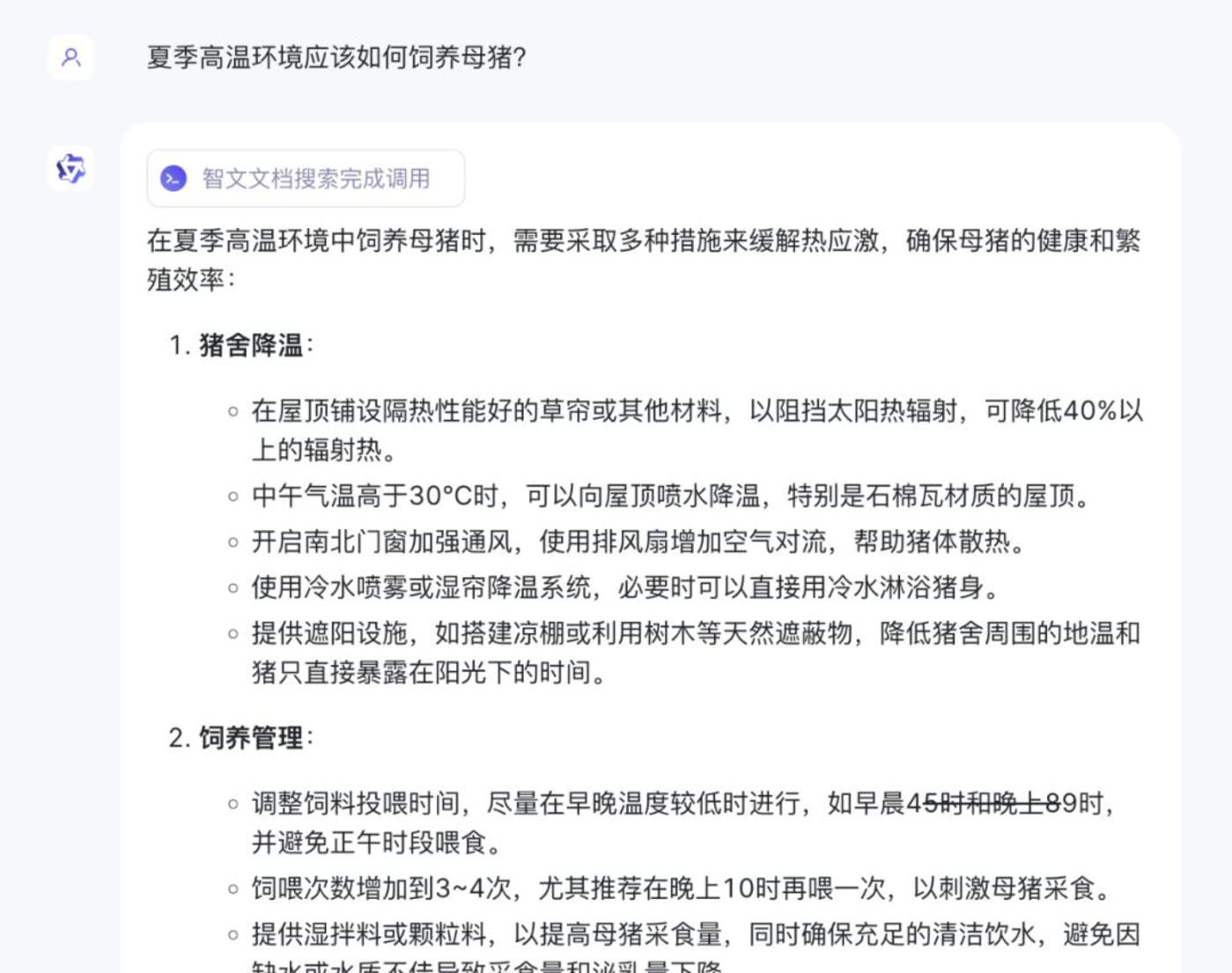
这意味着什么?只要用户有足够多的专业书籍“投喂”给大模型,那么大模型就可以成长为一个专业的专家助理,帮助用户快速解答相关专业问题。
在日常生活中,或许有很多书籍是我们没办法去仔细阅读和学习的,但是只要有长文本大模型予以支持,那么基本上人人都能创造一个专业的垂直领域助理。
这或许会颠覆现在我们获取信息、知识的渠道,去百度搜索或是去知乎提问、亦或是去小红书讨论这些路径都将被替代。
在 Kimi 开放 20 万字文本处理能力的时候,其做了一个简单的对比,20 万字等于什么?答案是等于先秦的全部古籍。随着长文本大模型进入百万量级的迭代,那么这些能力还能实现进一步的进化,对应所赋予场景应用的机会就是无限的。
如今,在 AI 领域,Agent 的话题也很火,被认为是下一个主流的应用形态。那么,打造 Agent 的关键是什么?答案正是大模型的长文本处理能力。
比如,Kimi 就在帮助元隆雅图等公司进行营销升级,基于长文本处理能力来提供爆品文案分析、文案写作、市场分析、辅助营销策划等功能。
尽管现在很多相关的应用还处在探索阶段,但是谁又能确定下一个爆款应用不是出自自家的大模型+某个C端用户的想法/某个企业客户的业务融合?正因如此,大模型厂商们才不顾一切的升级并开放长文本功能,为下一场应用上的爆火做准备。
目前,长本文的火爆还只是技术上的,接下来的爆点大概率将是应用上的爆发。
写在最后
2024 年是大模型大规模走向商业化的关键一年。从 Kimi 的火爆程度来看,以长文本为代表的技术迭代走向C端引发了非常积极的反馈。同时,在「智能相对论」的实践中,也预感这一能力随着技术的成熟和完善,必然会在C端用户的手中被“玩出花来”。
只是目前很多的“玩法”还缺乏打磨,显得比较粗糙。OpenAI 在发布 GPT 商店时,就期望要打造一个全新的生态,人人都能创造自己的专属 GPTs。
现在,摆在大众面前的长文本热潮,其实就是一个全民时代到来的信号。只要用户有书,会投喂,那么同样可以在国内的大模型平台上打造出属于自己想要的专业助理,进而延伸到应用端的火爆。
当然,在这个过程中,书籍的版权问题、平台的审核问题以及巨大的流量涌入所带来的诸多挑战和问题,也是大模型走向商业化的难点。但是,其根本的方向是清晰的,Long-LLM(长文本大模型)时代已经拉开序幕,从技术到应用,接下来大模型厂商们有得卷了。
说实在,就目前各大厂商公布的参数,从 500 万到 1000 万,基本上也足够用了。大模型在长文本技术层面或许不会再有什么值得卷了,哪怕是有也只是背地里正常迭代和发展。
接下来的爆点只能是往应用层面来看。不管是 To C 还是 To B,谁家的平台最先把大众化的应用探索并验证出来,再加以打磨推向大众市场,那么谁就有可能成为下一个市场的宠儿。